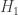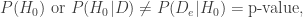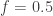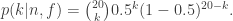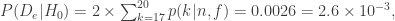Introduction
I just joined a competition called ‘Three Minute Thesis’ at my university, in which I have to explain, in three minutes, what my thesis is about*. The thing is that my thesis is about detecting exoplanet (that is, planets outside our solar system) atmospheres from the ground through an effect called transmission spectroscopy but, although that sounds cool for most people (except when I mention ‘transmission spectroscopy’, which sounds like a magical, frightening and strange word for non-astronomers), I don’t really know if they understand how hard this stuff is to do. In order to show this, I want to share a little order-of-magnitude calculation that I did in order to show how hard it is to find exoplanet atmospheres through this method.
What is transmission spectroscopy?
As of today, most exoplanets discovered so far have been discovered through the method of transits: the apparent decrease in flux of a star due to a planet passing in front of it. This is, of course, a lucky event: for earth-like planets (that is, planets orbiting Sun-like stars at the same distance as the Earth), assuming orbits around stars are totally random, the probability of finding a transiting planet is 

Diagram showing how light is not only blocked by a transiting planet during a transit event, but also how the atmospheric signature (red ring around the blue planet) is imprinted on the stellar light. Credits: Néstor Espinoza.
Seems like a cool effect, huh? It also seems like a very small effect. Let’s first explore how small of an effect a transiting planet makes and, then, jump into the very small effect the atmosphere might be able to produce!
The tiny effect of transits
Let’s consider a planet of radius 
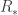
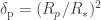

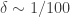
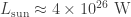
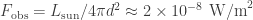
To compare this flux, let’s consider a lightbulb, which at best has an output of around 100 W. In order to observe a similar flux as that of the star mentioned before, you would need to be at a distance

from it. For the ones out there that have come to Santiago de Chile, this distance is roughly the distance from the top of San Cristobal hill to the farthest lightbulb you can see. This photo might enlighten your imagination:

Santiago de Chile as seen from San Cristóbal hill. Credits: Aldo Felipe Paez.
Pretty dim, huh? Now, how small is the effect of a 1% decrease in flux due to a transiting planet? Well, remember that a 1% decrease in flux for a star’s flux happens when a planet 1/10 of its radius passes in front of it when the star is like our Sun. The farthest lightbulb you can see in the photo comes from a source with a radius not bigger than, say, ~10 cm; a 1% decrease in flux in that lightbub then can arise from an object 1/10 of its size passing in front of it, or, an object with a radius of ~1 cm! That’s like detecting the effect of a moth passing between you and that lightbulb very close to it! That is a really small effect. However, as I mentioned in the introduction, most planets have been detected in this way, and there are large collaborations of astronomers trying to detect more exoplanets like these ones (have you ever heard of HATSouth, for example?). We might say that this is one of the most successful exoplanet finding tools to date! Now, If you think the effect of transits is small, wait until you see the really, really small effect that the atmosphere imprints on exoplanetary transits.
The (really) tiny effect of transmission spectroscopy
Let’s consider the same planet as before, but let’s now assume that it has an atmosphere. The effect that one usually wants to detect is the absorption feature of some atomic and/or molecular feature and, therefore, what one usually seeks is a transit event observed in different wavelengths. If there is absorption in a given wavelength, then the planet will look bigger than in other wavelengths. To simplify the matters, let’s assume that the whole atmosphere is of this given element that absorbs all the light at a given wavelength. If we assume that the only force that keeps this element from escaping to outer space is gravity, then it should be a given height where gravity is so small that the element can escape due to the internal kinetic energy of the compound. If the kinetic energy is of the same order of magnitude as the gravitational potential, then the gas will start escaping from the atmosphere. Assuming the element behaves more or less like an ideal gas and is more or less isothermal, the mean kinetic energy of it is given by
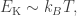
where 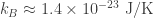


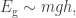
where 



This number is usually known as the scale height, and it defines a characteristic height to a given atmosphere (its actually the height at which an atmosphere in thermodynamic and hydrostatic equilibrium decreases its presure by a factor 
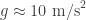
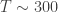
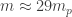
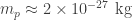
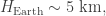
which is the characteristic height of our atmosphere. Of course, this is not the height of the whole atmosphere that would be probed by the effect of transmission spectroscopy; this largely depends on the constituents, layers and properties of those layers in each atmosphere (i.e., the pressure-temperature profile). As a good average between thin (
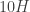
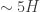


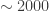
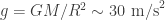
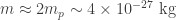
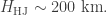
In this case then, if the atmosphere were to absorb all the light at a given wavelength, the planet would appear to have a radius of 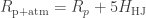
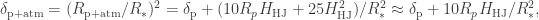
or, in a more compact form,
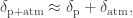
where we have ommited the 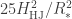
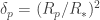
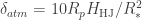
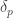
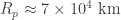

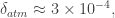
or 0.03%! That’s two orders of magnitude smaller than the transit signal 




passing close-by, in front and between us and the lightbulb. That’s measuring the effect of a 2 mm object passing in front of the lightbulb! Enough precision to give the moth a coat for the winter or a bathing suit for the summer! Despite the effect being very small, this effect has been measured successfully both from space and ground based observatories. However, these studies have been done only for a handful of systems; there are many more problems than just getting enough light from the stars in order to detect this effect, where ground based observations are by far the most challenging ones. Imagine trying to measure that 0.03% flux change from the lightbulb, but with fog, while your instrument moves, rotates and shakes due to its own gravity…those systematic effects are the biggest problems in current ground-based measurements. It’s quite a challenge, and that’s actually what makes it so interesting! Frontier science usually comes from beating those challenges with clever ideas so, stay tuned!
Conclusions
Detecting exoplanet atmospheres is hard. Very hard. In the best-case scenario, It is analogous to trying to measure the flux change in a lightbulb 20 km away from your location with enough precision to build a coat or a swimsuit for a moth passing in front and very close to the lightbulb. The signal depends largely on temperature, gravity and the mass of the elements in the atmosphere; it favours higher temperatures, lower gravities and lighter constituents. The biggest challenge, though, is not the signal but the actual systematic effects the instruments and the Earth’s atmosphere (for the case of ground-based observations) imprints on the signals but various groups of astronomers are working on this as we speak…stay tuned for future discoveries!
*: As an update on this, I won the People’s Choice award in the competition! It was really cool, specially because there was no people from my department in the audience (who were the ones who voted for me).
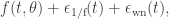
 , the second term is a zero mean 1/f stochastic process (which is defined by only one parameter,
, the second term is a zero mean 1/f stochastic process (which is defined by only one parameter, 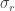 , which defines its amplitude but is not the square root of its variance), implying its Power Spectral Density is proportional to
, which defines its amplitude but is not the square root of its variance), implying its Power Spectral Density is proportional to 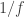 and the third term is a zero mean white noise process, here assumed to be gaussian (and hence with only one parameter defining it,
and the third term is a zero mean white noise process, here assumed to be gaussian (and hence with only one parameter defining it, 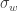 , the square root of its variance). Furthermore, the model assumes the time-sampling is uniform.
, the square root of its variance). Furthermore, the model assumes the time-sampling is uniform.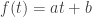 which has both additive white and 1/f noise. In the following plot, I have created 1/f noise following the method of
which has both additive white and 1/f noise. In the following plot, I have created 1/f noise following the method of 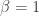 (in red), and I added white gaussian noise in order to make the problem even more challenging (black dots):
(in red), and I added white gaussian noise in order to make the problem even more challenging (black dots):
 and
and  , which is plotted in the following figure (you can
, which is plotted in the following figure (you can 

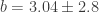
 : this is good! It is good because due to the correlated noise, we are very uncertain about the value (recall that the 1/f noise + white gaussian noise is a stochastic process and, as such, we only observe one realization of it; we can take into account this, but
: this is good! It is good because due to the correlated noise, we are very uncertain about the value (recall that the 1/f noise + white gaussian noise is a stochastic process and, as such, we only observe one realization of it; we can take into account this, but 
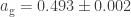
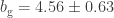
 ! This is BAD! What this shows (and you can generate more datasets and simulate this claim; which is actually something
! This is BAD! What this shows (and you can generate more datasets and simulate this claim; which is actually something